主題: R讀取中文檔案產生亂碼等錯誤問題
說明:
# read.table
# encoding="UTF-8-BOM"
# ANSI
# R程式碼:
說明:
# read.table
# encoding="UTF-8-BOM"
# ANSI
- 感謝R友-阿賢提供 encoding="UTF-8-BOM"解決亂碼問題.
- 使用R讀取文字檔時, 有時會遇到資料匯入有錯誤訊息或中文亂碼問題.
- 資料來源: https://data.gov.tw/dataset/35131, 匯入 open data 空氣品質監測小時值(一般污染物,每日更新) 所產生的問題與解決方式.
- 匯入資料 read.table {utils} 常用參數:
(1). fill = TRUE --> 使用時機: 錯誤訊息為 line x did not have xxx elements.
(2). encoding --> 結果為亂碼.
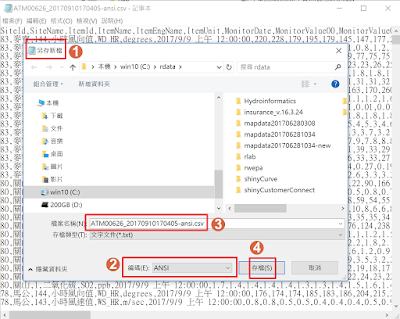
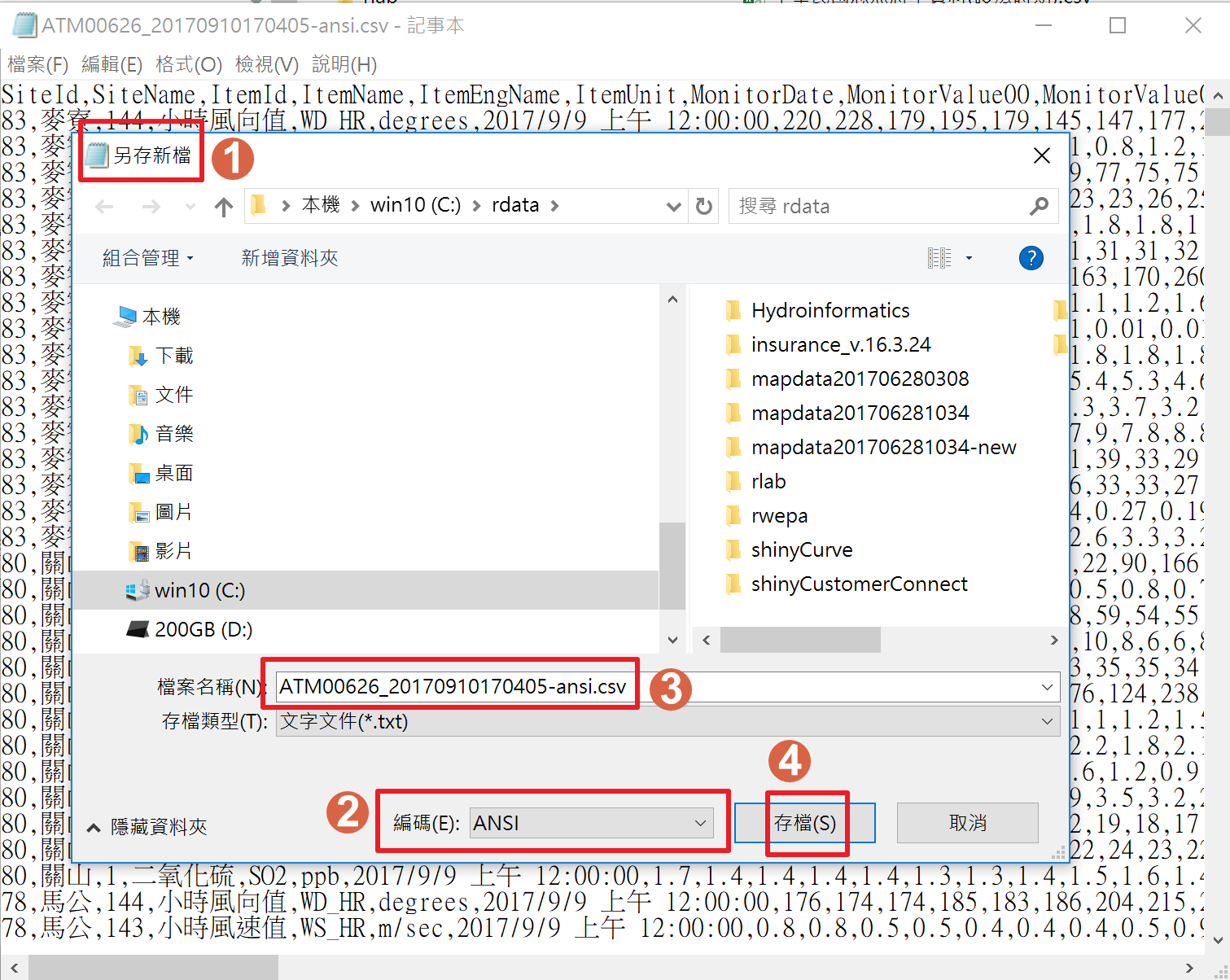
(3). fileEncoding --> 結果為亂碼. - 考慮 Windows 執行環境, 如果有亂碼問題, 最簡單的解決方式之一是使用記事本開啟檔案, 另存新檔 畫面中, 編碼改為 ANSI.
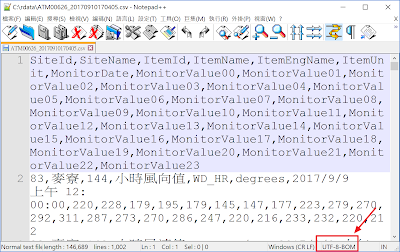
- 使用 Notepad++ [https://notepad-plus-plus.org/zh/] 開啟檔案, 在視窗右下角狀態列會有"UTF-8-BOM"編碼, 此時可加上 encoding 或 fileEncoding 參數, 本例使用 fileEncoding = "UTF-8-BOM" 參數即可完成匯入資料.
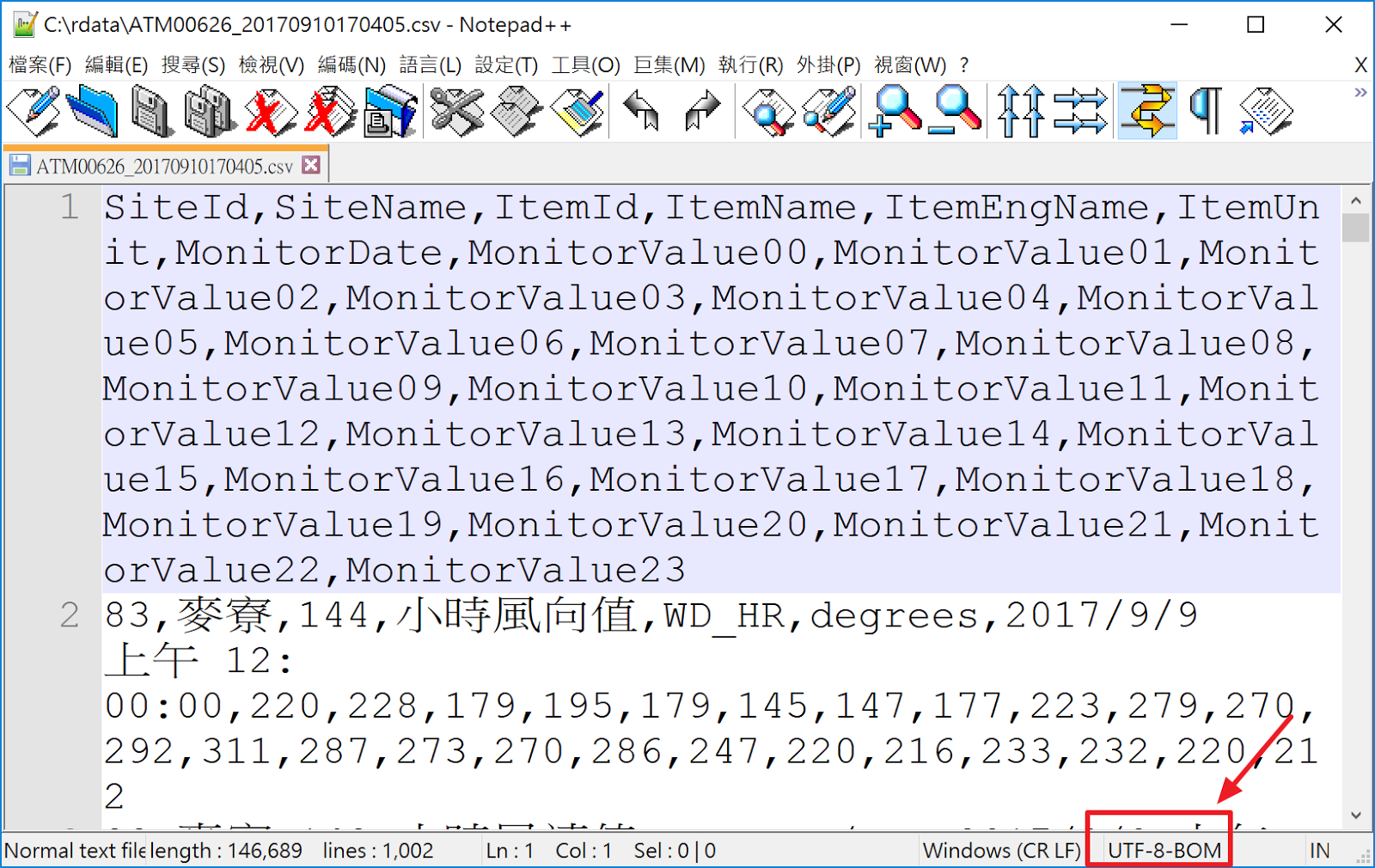
- 另可參考: 資料集為CSV檔,打開來為亂碼,怎麼辦? https://data.gov.tw/node/18765
- 結論: 使用另存ANSI編碼或加入fileEncoding="UTF-8-BOM"參數應該可以解決亂碼問題.
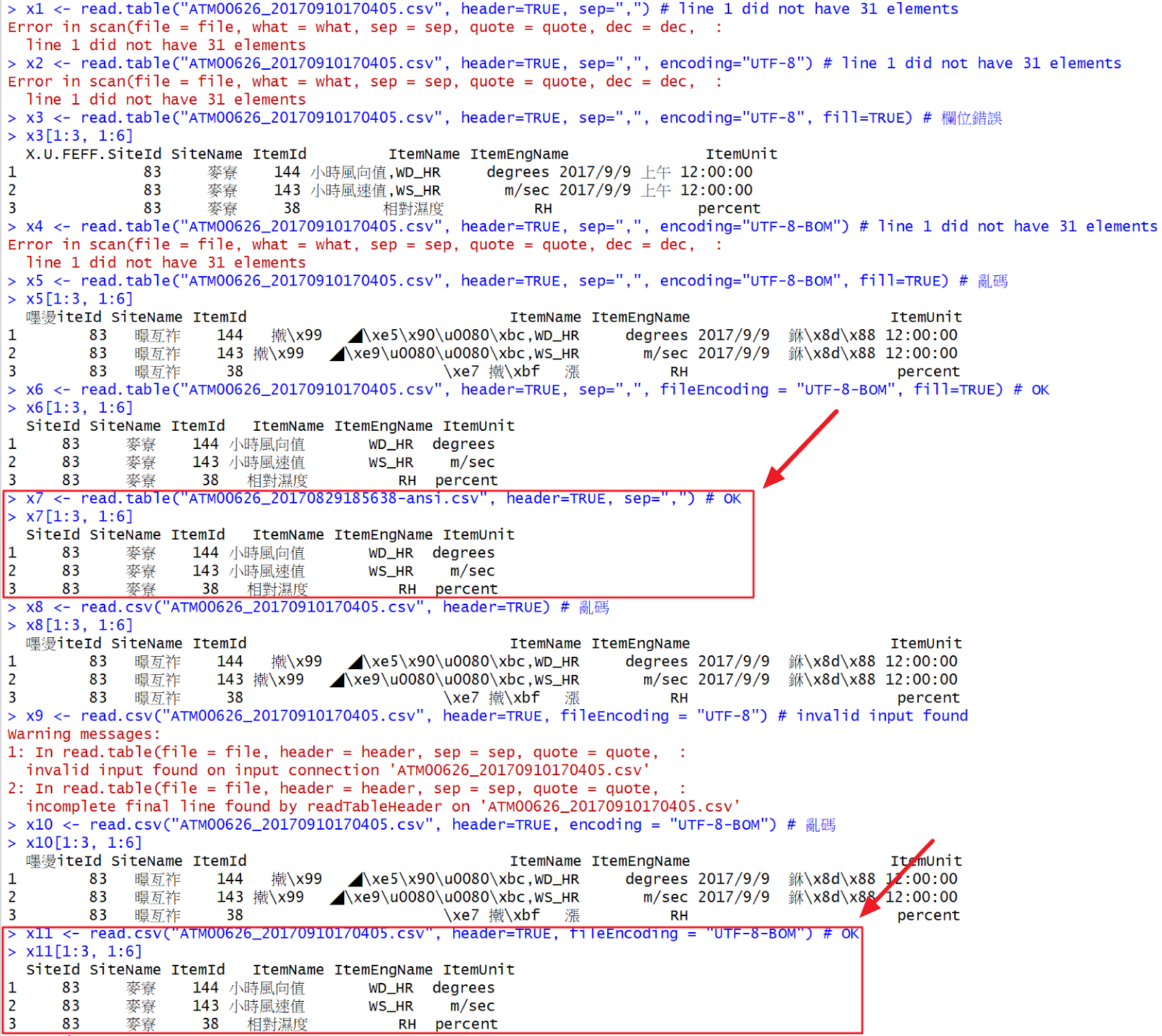
# R程式碼:
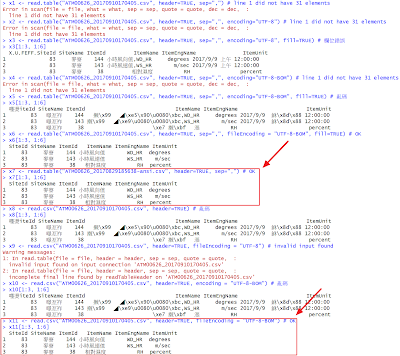
x1 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",") # line 1 did not have 31 elements
x2 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",", encoding="UTF-8") # line 1 did not have 31 elements
x3 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",", encoding="UTF-8", fill=TRUE) # 欄位錯誤
x3[1:3, 1:6]
x4 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",", encoding="UTF-8-BOM") # line 1 did not have 31 elements
x5 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",", encoding="UTF-8-BOM", fill=TRUE) # 亂碼
x5[1:3, 1:6]
x6 <- read.table("ATM00626_20170910170405.csv", header=TRUE, sep=",", fileEncoding = "UTF-8-BOM", fill=TRUE) # OK
x6[1:3, 1:6]
x7 <- read.table("ATM00626_20170829185638-ansi.csv", header=TRUE, sep=",") # OK
x7[1:3, 1:6]
x8 <- read.csv("ATM00626_20170910170405.csv", header=TRUE) # 亂碼
x8[1:3, 1:6]
x9 <- read.csv("ATM00626_20170910170405.csv", header=TRUE, fileEncoding = "UTF-8") # invalid input found
x10 <- read.csv("ATM00626_20170910170405.csv", header=TRUE, encoding = "UTF-8-BOM") # 亂碼
x10[1:3, 1:6]
x11 <- read.csv("ATM00626_20170910170405.csv", header=TRUE, fileEncoding = "UTF-8-BOM") # OK
x11[1:3, 1:6]
# end