R資料匯入與匯出
# read.table# read.csv
# read.fwf
# 檔首無BOM
# readxl 套件
# RODBC 套件
# lapply
# do.call
本篇說明資料匯入與匯出。首先介紹ETL概念,其次介紹常用的資料檔案,包括文字檔案、Excel檔案、資料庫資料、JSON檔案。資料庫的匯入將以Microsoft SQL Server說明為主。最後以單一檔案較大者的「大型資料」匯入與檔案數目較多者的「大量資料」匯入等議題做為本篇的結束。
1. ETL簡介
隨著科技的進步,企業經常面對資料處理、轉換或整合等應用。「ETL (Extract-Transform-Load)擷取轉換載入」是資料分析中的基礎的應用,最早興起於1970年資料倉儲中資料庫的處理程序。ETL表示資料由資料來源端擷取 (Extract) 出來,經過轉換 (Transform),再載入 (Load)到目的端的資料傳輸整體過程。進行ETL程序時,常用串流方式方法避免資料讀取時記憶體耗盡,參考圖1所示。
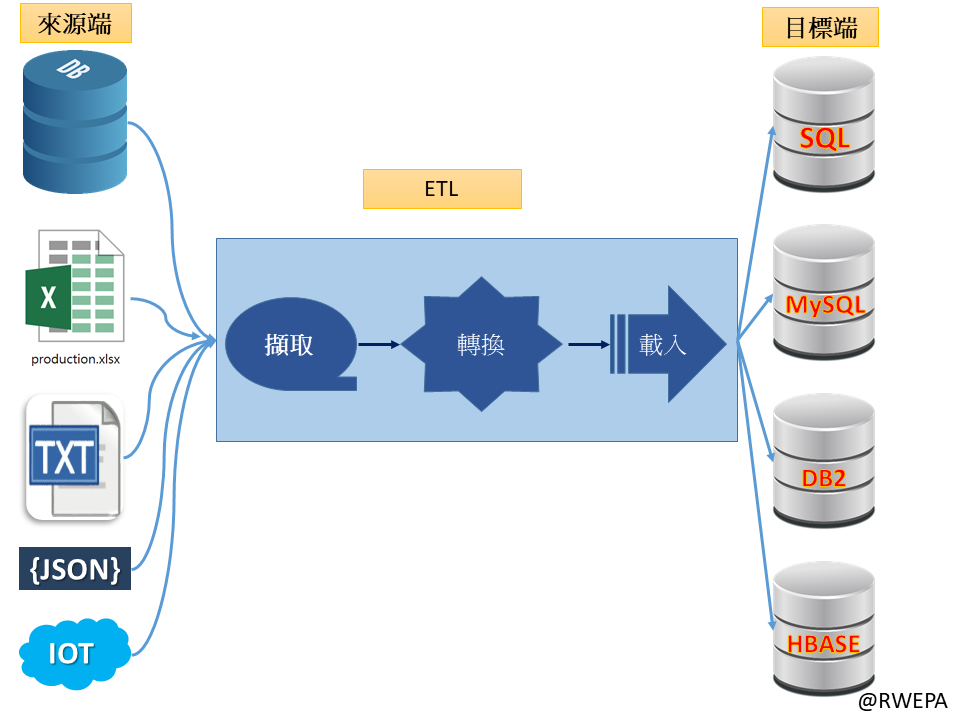
圖1 ETL流程圖
擷取:從各種不同的資料來源中,將資料擷取出來。資料來源包括交易型資料庫,同質資料與異質資料來源,資料擷取具有以下特性:
- 可能有各式各樣的資料來源和不同的資料格式,在利用程式語言開發或使用現有工具時,必須將來源資料轉換成共同資料格式。
- 擷取出來的資料,比對其格式和結構是否符合所需,例如:是固定欄位長度內容的資料、還是用區隔符號定義的資料。
- 擷取出來的資料若不符合所需,則依照相對應的規則以決定該採取何種反應,如:另外紀錄錯誤問題並發出警告,但整個ETL流程仍繼續執行。
- ETL作業能擷取一個檔案或同時進行多個來源端的資料擷取。
轉換:對資料進行適當的轉換,如型態轉換、字串相連、彙總運算等,本階段會將資料儲存成適當的格式,以利事後查詢與分析。這個步驟在 ETL 中不一定需要執行。
資料轉換具有以下特性:
- 可針對Excel、HTTP Web Page、XML、PDF與 Binary data 資料格式等檔案格式進行資料轉換。
- 基於商業邏輯上的需求,必須依照應用程式資料的特性來分類、匯總、轉換資料型態;或是把經年累月所聚集的歷史資料來作合併、統計、分折及計算。
- 本階段的轉換元件與功能通常是最多元、最豐富的,往往也是決定ETL產品的重要考量之一。
- 資料轉換就是將所擷取出之資料,交付予資料轉換元件(例:log資料轉換元件),逐一並循序地依照所設計好的規則進行轉換。
- 載入:將資料載入目的端,目的端通常是為了報表產製及商業智慧分析而最佳化的資料倉儲。
2. 文字檔案
常用的文字檔案包括以逗號分隔值檔案(Comma-Separated Values File,簡稱CSV File),其檔案以純文字形式儲存數字和文字資料。CSV檔案亦稱為字元分隔值檔案(Character-Separated Values File),因為分隔字元也可以不是逗號,例:分號(;)、Tab符號(–>)、bar符號(|)與空白字元。CSV檔案具有以下特性:- 採用純文字,使用某個字元集,例:ASCII、Unicode、UTF-8或GB2312(簡體中文環境)等儲存。
- 每一橫列為一筆記錄組成。
- 每一筆記錄以分隔符號區分欄位。
- 每一筆記錄都具有相同的欄位順序。
- 在Windows環境中使用 Microsft Office Excel 等軟體執行 檔案\另存新檔\存檔類型\ 選取「CSV(逗號分隔)()*.csv」 \ 按儲存 即可儲存為CSV檔案。
- 開啟CSV檔案時,最後一列為空白列,該空白列須保留不可刪除,否則匯入至R/Python會有問題。參考圖2,其中第12列為空白列。
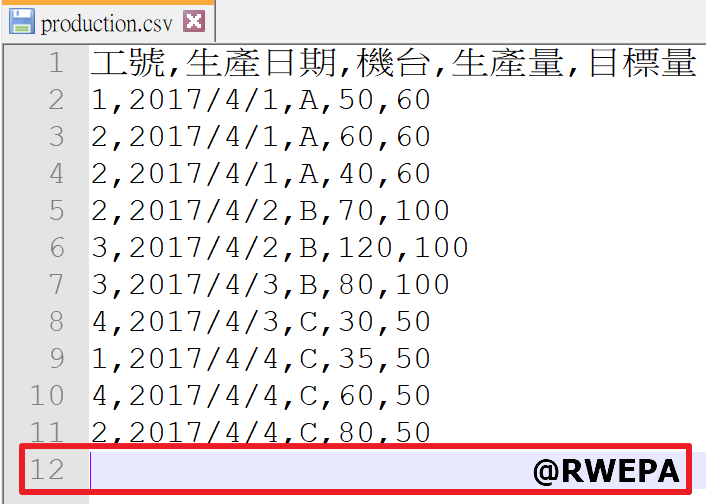
圖2 production.csv範例
範例1:匯入production.csv檔案。
CSV檔案匯入與資料分析工作包括以下五大步驟:
步驟1 設定工作目錄:
一般資料的匯入與匯出可以先考量工作目錄的概念。R/Python軟體具有工作目錄(Working Directory)概念,即預設讀取資料的目錄。以下說明以Windows 10作業系統與R軟體[https://www.r-project.org/]操作為主。使用getwd函數以取得工作目錄,設定工作目錄為setwd函數。本範例考慮工作目錄為「C:/rdata」。
setwd("C:/rdata")
getwd()
## [1] "C:/rdata"
步驟2 準備資料檔案:
本步驟為準備好即將匯入至R的資料檔案,一般初步使用建議將資料轉換為CSV檔案較方便於後續資料匯入。下載production.csv並儲存至C:\rdata,資料來源:http://web.ydu.edu.tw/~alan9956/rdata/production.csv。
步驟3 匯入資料:
常用匯入資料為read.table函數,使用彈性較大,read.csv函數為限用CSV檔案。本例使用read.table函數以匯入CSV檔案。“production.csv”表示檔案名稱,header=TRUE表示第一列為資料欄名稱,sep=“,”表示資料以逗號區隔欄位,stringsAsFactors=FALSE表示不會將字串自動轉換為因子(Factor),而保持原字串資料型態。匯入至R之資料物件名稱為production,資料顯示為10筆,5個欄位。如果匯入資料產生亂碼情形,則可考慮以下三種解決方式:
production <- read.table("production.csv", header=TRUE, sep=",", stringsAsFactors=FALSE)
production
## 工號 生產日期 機台 生產量 目標量
## 1 1 2017/4/1 A 50 60
## 2 2 2017/4/1 A 60 60
## 3 2 2017/4/1 A 40 60
## 4 2 2017/4/2 B 70 100
## 5 3 2017/4/2 B 120 100
## 6 3 2017/4/3 B 80 100
## 7 4 2017/4/3 C 30 50
## 8 1 2017/4/4 C 35 50
## 9 4 2017/4/4 C 60 50
## 10 2 2017/4/4 C 80 50
步驟4 資料分析:
資料匯入完成後,首要步驟是分別使用str函數與summary函數進行資料結構理解與統計摘要分析。int表示整數(Integer),chr表示字串(String)或稱為字元(Chacter)。summary函數會輸出以下6個統計量:
str(production)
## 'data.frame': 10 obs. of 5 variables:
## $ 工號 : int 1 2 2 2 3 3 4 1 4 2
## $ 生產日期: chr "2017/4/1" "2017/4/1" "2017/4/1" "2017/4/2" ...
## $ 機台 : chr "A" "A" "A" "B" ...
## $ 生產量 : int 50 60 40 70 120 80 30 35 60 80
## $ 目標量 : int 60 60 60 100 100 100 50 50 50 50
summary(production)
## 工號 生產日期 機台 生產量
## Min. :1.0 Length:10 Length:10 Min. : 30.0
## 1st Qu.:2.0 Class :character Class :character 1st Qu.: 42.5
## Median :2.0 Mode :character Mode :character Median : 60.0
## Mean :2.4 Mean : 62.5
## 3rd Qu.:3.0 3rd Qu.: 77.5
## Max. :4.0 Max. :120.0
## 目標量
## Min. : 50
## 1st Qu.: 50
## Median : 60
## Mean : 68
## 3rd Qu.: 90
## Max. :100
# 新增達成率欄位,計算方式為生產量/目標量
production$達成率 <- round((production$生產量/production$目標量)*100)
production
## 工號 生產日期 機台 生產量 目標量 達成率
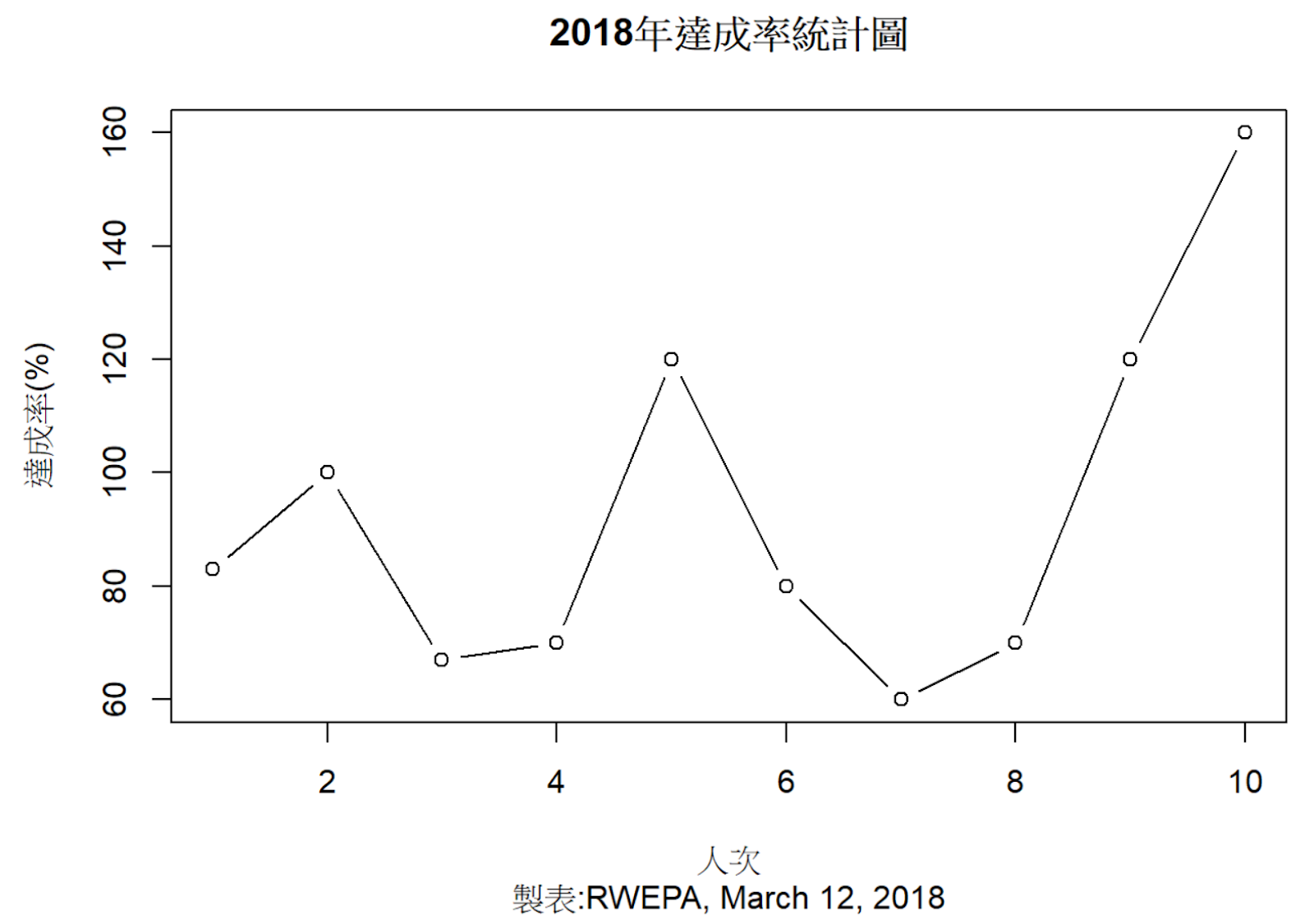
## 1 1 2017/4/1 A 50 60 83
## 2 2 2017/4/1 A 60 60 100
## 3 2 2017/4/1 A 40 60 67
## 4 2 2017/4/2 B 70 100 70
## 5 3 2017/4/2 B 120 100 120
## 6 3 2017/4/3 B 80 100 80
## 7 4 2017/4/3 C 30 50 60
## 8 1 2017/4/4 C 35 50 70
## 9 4 2017/4/4 C 60 50 120
## 10 2 2017/4/4 C 80 50 160
# 繪製達成率統計圖
plot(production$達成率, xlab="人次", ylab="達成率(%)", main="2018年達成率統計圖", type="b", sub="製表:RWEPA, March 12, 2018")

步驟5 匯出分析結果:
最後步驟是將分析的結果,包括文字與圖檔等進行資料匯出,常用的文字資料匯出函數是write.table與R專用資料格式(RData)save函數。本例使用write.table函數 匯出成production.output.csv檔案,使用save函數匯出成production.output.RData。
write.table(production, file="production.output.csv", sep=",", row.names=TRUE)
save(production, file="production.output.RData")
如果文字檔案是採用固定寬定方式儲存,則匯入資料時可採用 read.fwf 函數匯入。例:固定寬度檔案名稱是 myfix.txt,資料寬度分別為1, 2, 3個空白字元, 4個字元,則匯入方法如下,其中 -3 表示跳過3行不讀取:
範例2:匯入 production.xlsx 檔案。
首先將範例1的 production.csv 另儲存成 production.xlsx。使用 excel_sheets函數理解工作表個數,使用 read_excel讀取工作表,其中mydf1,mydf2,mydf3結果皆相同。
library(readxl)
# 顯示工作表名稱
datasets <- "production.xlsx"
excel_sheets(datasets)
## [1] "production"
# 讀取Excel檔案
mydf1 <- read_excel(datasets) # 預設讀取第1個工作表
mydf2 <- read_excel(datasets, 1) # 指定第1個工作表
mydf3 <- read_excel(datasets, "production") # 指定工作表名稱
mydf1
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
mydf2
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
mydf3
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
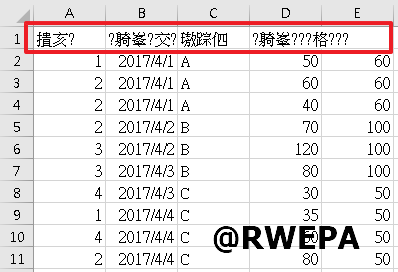
範例3:參考圖3,使用Excel開啟CSV檔案會有亂碼情形。
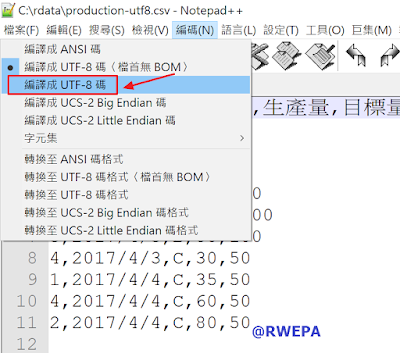
改善方式之一是考慮使用文字編輯軟體,修改編碼方式,本例使用免費軟體Notepad++,將編碼由原先的「編譯成UTF-8碼(檔首無BOM)」修改為「編譯成 UTF-8 碼」,再儲存檔案後使用Excel開啟即沒有亂碼,詳細參考圖4之設定。
關於微軟(Microsoft)大量結構性資料匯入與匯出,Microsoft SQL Server提供以下工具:
資料來源:https://docs.microsoft.com/zh-tw/sql/relational-databases/import-export/bulk-import-and-export-of-data-sql-server
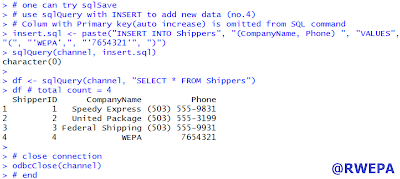
R可採用 RODBC 套件與Microsoft SQL Server資料庫連結,其中 sqlQuery 函數可執行資料匯入至R/R物件寫入SQL資料庫,部分執行畫面參考圖5,詳細參考 RODBC 與 SQL Server 資料匯入與寫入。
JSON(JavaScript Object Notation)是一種由Douglas Crockford 構想和設計、輕量級的資料交換語言,該語言以易於讓人閱讀的文字為基礎,用來傳輸由屬性值或者序列性的值組成的資料物件。儘管JSON是Javascript的一個子集,但JSON是獨立於語言的文字格式,並且採用了類似於C語言家族的一些習慣,詳細參考官方網站[http://www.json.org/]
資料來源:https://en.wikipedia.org/wiki/JSON。
JSON資料物件包括:
JSON資料型態包括:
RJSONIO 套件提供以下二大函數,詳細參考函數線上說明:
JSON資料參考圖1.4.6 JSON-錄影節目影片範例。
資料來源:http://vida.moc.gov.tw/VIDA411.ASP?ISSUEYM=10306
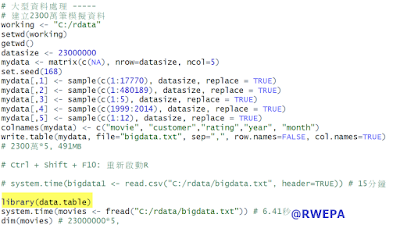
大型資料指的是單一檔案較大,使用傳統read.table或read.csv函數可能匯入時間教長,此時可使用data.table套件的fread函數以提升匯入效能,詳細參考以下圖7 大型資料範例。
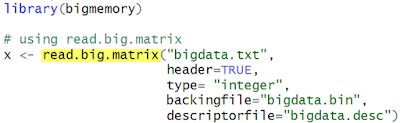
上述大型資料亦可使用 bigmemory套件匯入資料,參考圖8 大型資料-bigmemory範例。
大量資料指的是檔案較多時,使用傳統 read.table或 read.csv函數逐一匯入較不方便,此時可使用 lapply函數,詳細參考以下大量資料範例,考慮將三個檔案,每個檔案是10列5行,合併為單一資料物件30列5行。
lapply 函數主要包括2個參數 lapply(資料物件, 函數),其回傳結果是串列(list):
do.call 函數是將三個串列合併為一個資料框(data.frame)。
# 大量資料範例
working_path <- "C:/rdata"
setwd(working_path)
getwd()
## [1] "C:/rdata"
sample1 <- iris[sample(1:nrow(iris),10),]
sample2 <- iris[sample(1:nrow(iris),10),]
sample3 <- iris[sample(1:nrow(iris),10),]
write.table(sample1, file="sample1.csv", sep=",", row.names=FALSE)
write.table(sample2, file="sample2.csv", sep=",", row.names=FALSE)
write.table(sample3, file="sample3.csv", sep=",", row.names=FALSE)
files <- dir(getwd(), pattern="sample.*.csv", recursive=TRUE, full.names=TRUE)
files
## [1] "C:/rdata/sample1.csv" "C:/rdata/sample2.csv" "C:/rdata/sample3.csv"
tables <- lapply(files, read.table, header=TRUE, sep=",") # list
sample.all <- do.call(rbind, tables) # data.frame
str(sample.all)
## 'data.frame': 30 obs. of 5 variables:
## $ Sepal.Length: num 5.4 4.7 5.7 6.3 6.6 7 5 4.4 5.4 6.3 ...
## $ Sepal.Width : num 3.9 3.2 2.8 2.5 3 3.2 3.6 3 3 2.5 ...
## $ Petal.Length: num 1.7 1.3 4.1 5 4.4 4.7 1.4 1.3 4.5 4.9 ...
## $ Petal.Width : num 0.4 0.2 1.3 1.9 1.4 1.4 0.2 0.2 1.5 1.5 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 2 3 2 2 1 1 2 2 ...
# end
setwd("C:/rdata")
getwd()
## [1] "C:/rdata"
步驟2 準備資料檔案:
本步驟為準備好即將匯入至R的資料檔案,一般初步使用建議將資料轉換為CSV檔案較方便於後續資料匯入。下載production.csv並儲存至C:\rdata,資料來源:http://web.ydu.edu.tw/~alan9956/rdata/production.csv。
步驟3 匯入資料:
常用匯入資料為read.table函數,使用彈性較大,read.csv函數為限用CSV檔案。本例使用read.table函數以匯入CSV檔案。“production.csv”表示檔案名稱,header=TRUE表示第一列為資料欄名稱,sep=“,”表示資料以逗號區隔欄位,stringsAsFactors=FALSE表示不會將字串自動轉換為因子(Factor),而保持原字串資料型態。匯入至R之資料物件名稱為production,資料顯示為10筆,5個欄位。如果匯入資料產生亂碼情形,則可考慮以下三種解決方式:
- 使用記事本等軟體,將資料另存新檔且編碼設定為ANSI。
- 在read.table函數中加入 fileEncoding=“UTF-8”或適當編碼。
- 在read.table函數中加入 encoding=“UTF-8”或適當編碼。
production <- read.table("production.csv", header=TRUE, sep=",", stringsAsFactors=FALSE)
production
## 工號 生產日期 機台 生產量 目標量
## 1 1 2017/4/1 A 50 60
## 2 2 2017/4/1 A 60 60
## 3 2 2017/4/1 A 40 60
## 4 2 2017/4/2 B 70 100
## 5 3 2017/4/2 B 120 100
## 6 3 2017/4/3 B 80 100
## 7 4 2017/4/3 C 30 50
## 8 1 2017/4/4 C 35 50
## 9 4 2017/4/4 C 60 50
## 10 2 2017/4/4 C 80 50
步驟4 資料分析:
資料匯入完成後,首要步驟是分別使用str函數與summary函數進行資料結構理解與統計摘要分析。int表示整數(Integer),chr表示字串(String)或稱為字元(Chacter)。summary函數會輸出以下6個統計量:
- Min :最小值(Minimum)
- 1st Qu :25百分位數,符號 Q1
- Median :中位數,符號 Q2
- Mean :平均數
- 3rd Qu :75百分數位,符號 Q3
- Max :最大值(Maximum)
str(production)
## 'data.frame': 10 obs. of 5 variables:
## $ 工號 : int 1 2 2 2 3 3 4 1 4 2
## $ 生產日期: chr "2017/4/1" "2017/4/1" "2017/4/1" "2017/4/2" ...
## $ 機台 : chr "A" "A" "A" "B" ...
## $ 生產量 : int 50 60 40 70 120 80 30 35 60 80
## $ 目標量 : int 60 60 60 100 100 100 50 50 50 50
summary(production)
## 工號 生產日期 機台 生產量
## Min. :1.0 Length:10 Length:10 Min. : 30.0
## 1st Qu.:2.0 Class :character Class :character 1st Qu.: 42.5
## Median :2.0 Mode :character Mode :character Median : 60.0
## Mean :2.4 Mean : 62.5
## 3rd Qu.:3.0 3rd Qu.: 77.5
## Max. :4.0 Max. :120.0
## 目標量
## Min. : 50
## 1st Qu.: 50
## Median : 60
## Mean : 68
## 3rd Qu.: 90
## Max. :100
# 新增達成率欄位,計算方式為生產量/目標量
production$達成率 <- round((production$生產量/production$目標量)*100)
production
## 工號 生產日期 機台 生產量 目標量 達成率
## 1 1 2017/4/1 A 50 60 83
## 2 2 2017/4/1 A 60 60 100
## 3 2 2017/4/1 A 40 60 67
## 4 2 2017/4/2 B 70 100 70
## 5 3 2017/4/2 B 120 100 120
## 6 3 2017/4/3 B 80 100 80
## 7 4 2017/4/3 C 30 50 60
## 8 1 2017/4/4 C 35 50 70
## 9 4 2017/4/4 C 60 50 120
## 10 2 2017/4/4 C 80 50 160
# 繪製達成率統計圖
plot(production$達成率, xlab="人次", ylab="達成率(%)", main="2018年達成率統計圖", type="b", sub="製表:RWEPA, March 12, 2018")
步驟5 匯出分析結果:
最後步驟是將分析的結果,包括文字與圖檔等進行資料匯出,常用的文字資料匯出函數是write.table與R專用資料格式(RData)save函數。本例使用write.table函數 匯出成production.output.csv檔案,使用save函數匯出成production.output.RData。
write.table(production, file="production.output.csv", sep=",", row.names=TRUE)
save(production, file="production.output.RData")
如果文字檔案是採用固定寬定方式儲存,則匯入資料時可採用 read.fwf 函數匯入。例:固定寬度檔案名稱是 myfix.txt,資料寬度分別為1, 2, 3個空白字元, 4個字元,則匯入方法如下,其中 -3 表示跳過3行不讀取:
read.fwf("myfix.txt", widths = c(1, 2, -3, 4))3. Excel檔案
Excel檔案是常用辦公室資料檔案格式,除了以Microsoft Office Excel軟體進行操作,另外可使用readxl套件匯入Excel檔案並進行資料操作處理。範例2:匯入 production.xlsx 檔案。
首先將範例1的 production.csv 另儲存成 production.xlsx。使用 excel_sheets函數理解工作表個數,使用 read_excel讀取工作表,其中mydf1,mydf2,mydf3結果皆相同。
library(readxl)
# 顯示工作表名稱
datasets <- "production.xlsx"
excel_sheets(datasets)
## [1] "production"
# 讀取Excel檔案
mydf1 <- read_excel(datasets) # 預設讀取第1個工作表
mydf2 <- read_excel(datasets, 1) # 指定第1個工作表
mydf3 <- read_excel(datasets, "production") # 指定工作表名稱
mydf1
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
mydf2
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
mydf3
## # A tibble: 10 x 5
## 工號 生產日期 機台 生產量 目標量
## <dbl> <dttm> <chr> <dbl> <dbl>
## 1 1.00 2017-04-01 00:00:00 A 50.0 60.0
## 2 2.00 2017-04-01 00:00:00 A 60.0 60.0
## 3 2.00 2017-04-01 00:00:00 A 40.0 60.0
## 4 2.00 2017-04-02 00:00:00 B 70.0 100
## 5 3.00 2017-04-02 00:00:00 B 120 100
## 6 3.00 2017-04-03 00:00:00 B 80.0 100
## 7 4.00 2017-04-03 00:00:00 C 30.0 50.0
## 8 1.00 2017-04-04 00:00:00 C 35.0 50.0
## 9 4.00 2017-04-04 00:00:00 C 60.0 50.0
## 10 2.00 2017-04-04 00:00:00 C 80.0 50.0
範例3:參考圖3,使用Excel開啟CSV檔案會有亂碼情形。
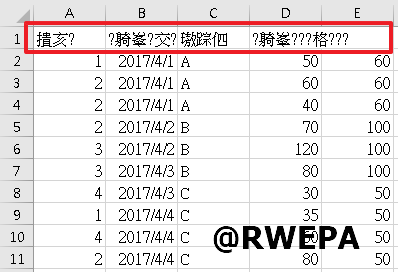
圖3 CSV檔案亂碼
改善方式之一是考慮使用文字編輯軟體,修改編碼方式,本例使用免費軟體Notepad++,將編碼由原先的「編譯成UTF-8碼(檔首無BOM)」修改為「編譯成 UTF-8 碼」,再儲存檔案後使用Excel開啟即沒有亂碼,詳細參考圖4之設定。
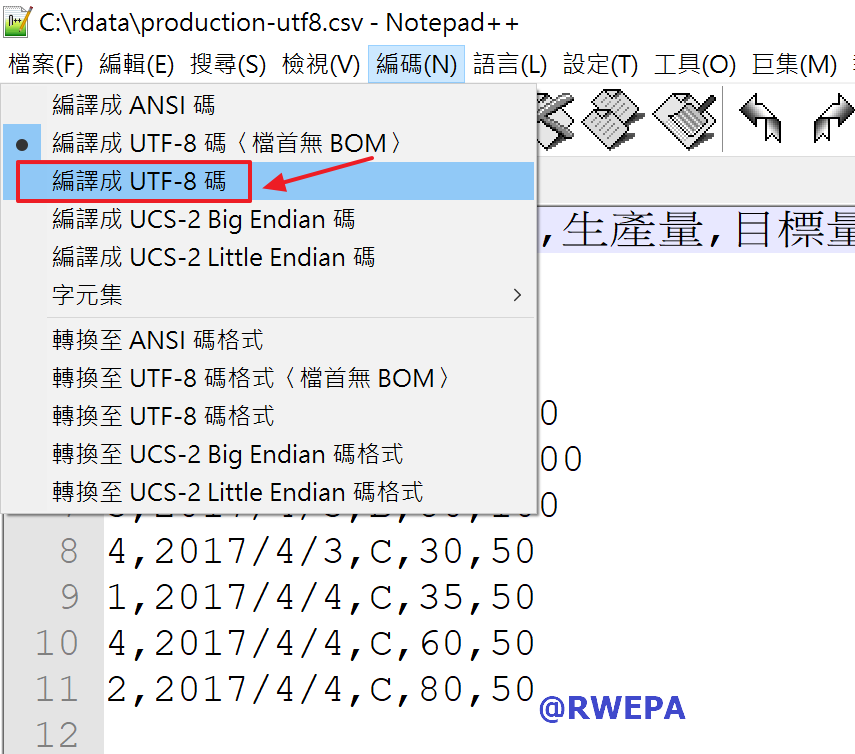
圖4 CSV檔案亂碼-UTF-8
4. 資料庫資料
關於微軟(Microsoft)大量結構性資料匯入與匯出,Microsoft SQL Server提供以下工具:
- bcp公用程式 (bulk copy program): 提供大量資料匯入與匯出功能,可以由使用者指定格式,在 Microsoft SQL Server 執行個體與資料檔案之間大量複製資料。
- BULK INSERT 陳述式:可將資料直接從資料檔案匯入至資料庫資料表或非資料分割的檢視,不提供匯出資料功能。
- BULK INSERT 陳述式與 INSERT…SELECT * FROM OPENROWSET(BULK…) 陳述式 :將大量資料檔案匯入到 SQL Server 資料表中,不提供匯出資料功能。
- SQL Server Data Tools (SSDT) 來執行 SQL Server 匯入和匯出精靈。
資料來源:https://docs.microsoft.com/zh-tw/sql/relational-databases/import-export/bulk-import-and-export-of-data-sql-server
R可採用 RODBC 套件與Microsoft SQL Server資料庫連結,其中 sqlQuery 函數可執行資料匯入至R/R物件寫入SQL資料庫,部分執行畫面參考圖5,詳細參考 RODBC 與 SQL Server 資料匯入與寫入。
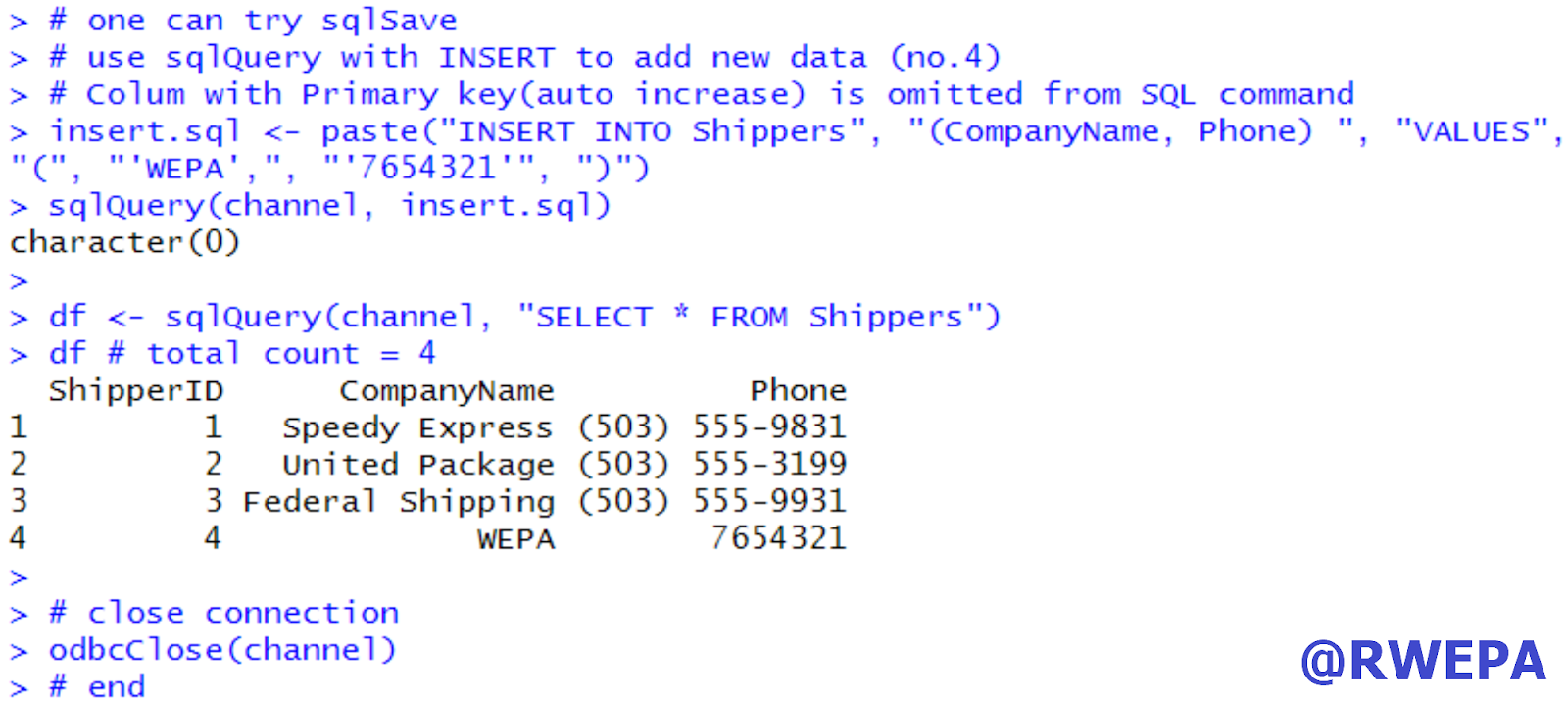
圖5 RODBC-寫入
5. JSON檔案
JSON(JavaScript Object Notation)是一種由Douglas Crockford 構想和設計、輕量級的資料交換語言,該語言以易於讓人閱讀的文字為基礎,用來傳輸由屬性值或者序列性的值組成的資料物件。儘管JSON是Javascript的一個子集,但JSON是獨立於語言的文字格式,並且採用了類似於C語言家族的一些習慣,詳細參考官方網站[http://www.json.org/]
資料來源:https://en.wikipedia.org/wiki/JSON。
JSON資料物件包括:
- 物件 object : {name:value}
- 陣列 array : [x1, x2, …]
JSON資料型態包括:
- 空值(null)。
- 邏輯值(true, false)暨布林值。
- 數值(number),沒有區分整數與具有小數點數。
- 字串(string)。
RJSONIO 套件提供以下二大函數,詳細參考函數線上說明:
- toJSON() : 轉換 R 物件為 JSON 字串。
- fromJSON() : 轉換 JSON物件為 R 物件, 資料來源包括 URL, File, R物件。
JSON資料參考圖1.4.6 JSON-錄影節目影片範例。

圖6 JSON-錄影節目影片範例
資料來源:http://vida.moc.gov.tw/VIDA411.ASP?ISSUEYM=10306
6. 大型資料
大型資料指的是單一檔案較大,使用傳統read.table或read.csv函數可能匯入時間教長,此時可使用data.table套件的fread函數以提升匯入效能,詳細參考以下圖7 大型資料範例。
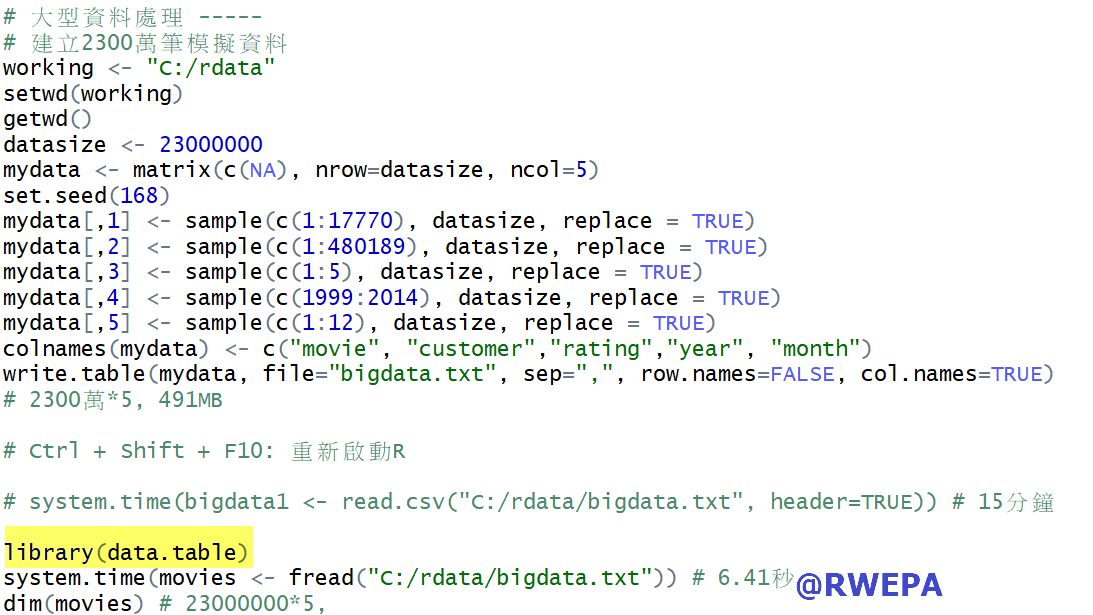
圖7 大型資料範例
上述大型資料亦可使用 bigmemory套件匯入資料,參考圖8 大型資料-bigmemory範例。
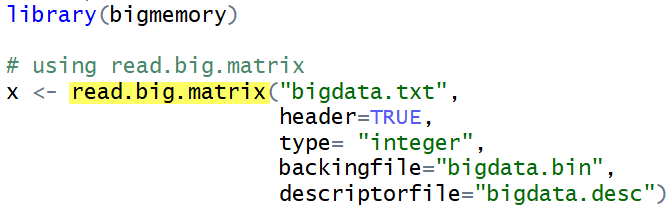
圖8 大型資料-bigmemory範例
7. 大量資料
大量資料指的是檔案較多時,使用傳統 read.table或 read.csv函數逐一匯入較不方便,此時可使用 lapply函數,詳細參考以下大量資料範例,考慮將三個檔案,每個檔案是10列5行,合併為單一資料物件30列5行。
lapply 函數主要包括2個參數 lapply(資料物件, 函數),其回傳結果是串列(list):
- 第一個參數是須要處理的資料物件,一般是向量資料,本例 files 表示三個檔案路徑。
- 第二個參數是函數,本例是 read.table,後續 「header=TRUE, sep="," 」是配合 raed.table使用。
do.call 函數是將三個串列合併為一個資料框(data.frame)。
# 大量資料範例
working_path <- "C:/rdata"
setwd(working_path)
getwd()
## [1] "C:/rdata"
sample1 <- iris[sample(1:nrow(iris),10),]
sample2 <- iris[sample(1:nrow(iris),10),]
sample3 <- iris[sample(1:nrow(iris),10),]
write.table(sample1, file="sample1.csv", sep=",", row.names=FALSE)
write.table(sample2, file="sample2.csv", sep=",", row.names=FALSE)
write.table(sample3, file="sample3.csv", sep=",", row.names=FALSE)
files <- dir(getwd(), pattern="sample.*.csv", recursive=TRUE, full.names=TRUE)
files
## [1] "C:/rdata/sample1.csv" "C:/rdata/sample2.csv" "C:/rdata/sample3.csv"
tables <- lapply(files, read.table, header=TRUE, sep=",") # list
sample.all <- do.call(rbind, tables) # data.frame
str(sample.all)
## 'data.frame': 30 obs. of 5 variables:
## $ Sepal.Length: num 5.4 4.7 5.7 6.3 6.6 7 5 4.4 5.4 6.3 ...
## $ Sepal.Width : num 3.9 3.2 2.8 2.5 3 3.2 3.6 3 3 2.5 ...
## $ Petal.Length: num 1.7 1.3 4.1 5 4.4 4.7 1.4 1.3 4.5 4.9 ...
## $ Petal.Width : num 0.4 0.2 1.3 1.9 1.4 1.4 0.2 0.2 1.5 1.5 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 2 3 2 2 1 1 2 2 ...
# end
PREVIOUSR的arguments出現三個點是...?